Crowdsourcing information system for camellia cultivar identification
Ventura A.1, Campos G.1,2, Zagalo H.1,2
1 DETI - Departamento de Electrónica, Telecomunicações e Informática
2 IEETA - Instituto de Engenharia Electrónica e Telemática de Aveiro
Universidade de Aveiro, Campus de Santiago, 3810-193 Portugal
E-mail: andrefv@ua.pt
1. Introduction
The breeding and naming of new camellia varieties has been going on for centuries. The efforts put into camellia cultivar identification stem from the natural curiosity of owners and aficionados about the origin of different specimens. Cultivar identification can also add economic value, because there is growing interest in plants with historical provenance and, as pointed out in [1] with regard to Cornwall (where tourism is the single most lucrative industry), garden visitors are prepared to pay a premium for complete, reliable information about them. The same paper also deplores the fact that camellias are often propagated and sold unidentified or – even worse – wrongly identified. The importance attributed to this subject is reflected in the criteria set by the ICS for Gardens of Excellence (GoE). A camellia GoE must have a minimum collection of 200 cultivars or species, all with identifying labels, and maintain a register of every specimen and their location [2]. Obviously, the GoE accolade itself is a valuable visitor attraction.
However, even without considering variations due to growing conditions (e.g. soil, climate) and sporting, camellia cultivar identification is a very demanding challenge. The first obstacle is the huge number of cultivars developed and recorded over the centuries. The ICS’s International Camellia Register (ICR), a result of 50 years of painstaking data collection [3], publicly available online since 2008 as the Web Camellia Register [4] lists over 20,000 entries. But the main difficulty is the lack of complete, systematic information about those registered cultivars. The temporal span covered by the ICR is enormous; its entries are essentially text descriptions taken from catalogues which, barring occasional references to paintings or photographs, are normally rather incomplete, with disparate levels of detail. With no formal structure support for this information, there is no systematic way of searching for matches based on given specimen characteristics, making identification, even tentative, virtually impossible.
A crucial step in the massive task of filling in the missing information is to establish standard specimens of the cultivars. This is another tricky problem; recent research case-studies using DNA testing have found specimens deemed to be of the same cultivar, producing seemingly identical flowers, that actually belonged to different camellia varieties [5]. Many ICR entries, especially the older ones, may be affected by this problem.
Countless identification studies have been reported in the literature; examples can be easily found in recent issues of the International Camellia Journal (ICJ), such as [1], [6] and [7], to name only a few. The difficulty of the subject is invariably confirmed. Also, camellia-related websites tend to be poorly maintained and offer very disparate and incomplete identification data. Creating an efficient, easy-to-use and reliable cultivar identification system is the aim of this project. Considering all the difficulties summarised above and previous projects addressing this problem, it is clear that:
1) It cannot be achieved through disjointed individual efforts. It must be able to draw contributions from the whole camellia community, integrating the collected pieces of information in a single repository shared at global level.
2) It must be acknowledged as a long-term aim, because it can only be implemented gradually.
3) Information and communication technology (ICT) is a key tool for this purpose.
ICT is sometimes regarded as a panacea for all sorts of problems, but the strategy proposed here, although it does involve an information system of camellia specimens fed online, is by no means based on that misconception. Cultivar identification relies on the collaborative work of camellia aficionados and, essential as they may be, computers and Internet communication are just tools to promote and assist that collective effort. The key concept here is crowdsourcing.
2. Crowdsourcing
The term crowdsourcing, used for the first time in 2006 by the journalist Jeff Howe [8], refers to the practice of obtaining services, ideas or data content through the contribution of a large number of people, especially in online communities. The most remarkable and well-known example is undoubtedly the Wikipedia, the online encyclopedia whose content can be created, reviewed and improved by anyone. The success of this revolutionary concept is the best demonstration that information and communication technologies have the power to involve communities in tasks that would otherwise be extremely hard or even impossible to accomplish.
Crowdsourcing is proving useful in increasingly diverse areas of application. An interesting example along similar lines to those proposed here is the Treezilla project [9], based on the OpenTreeMap engine [10], whose purpose is to identify and map every tree in the UK, in an effort to raise awareness on the benefits of trees to the local environment.
3. System structure and basic operation
The proposed solution is based on an online information system serving a community of registered users, built around and providing support to the following key elements:
• A specimen database;
• Cultivar identification requests;
• Cultivar identification quizzes;
• Cultivar register based on the ICR.
The specimen database is fed primarily by identification requests submitted by users. The community will be challenged to try and answer those requests through cultivar identification quizzes generated automatically. Respondents must choose from the system’s cultivar register. To avoid loading the entire ICR beforehand, the register may be dynamic, allowing respondents to add new cultivar names, which will only become permanent after approval by system moderators.
The quizzes are presented as identification expertise tests for entertainment, displaying flower photos and allowing access to additional information from the database entries under scrutiny – see example in Figure 1.
 Figure 1. Cultivar identification quiz.
Figure 1. Cultivar identification quiz.
Statistical analysis of the answered quizzes will provide educated cultivar identification guesses. Metrics will be established to rate both the probability of correct cultivar identification and the identification expertise (reputation) of respondents (see section 6). As newly-answered quizzes are taken into account, the system will be able to update these two ratings dynamically and also automatically notify the users concerned (id. requesters or quiz respondents) of any changes deemed significant. The expectation is that, as information becomes increasingly reliable, this will generate a ‘virtuous cycle’ of contributions to the system. Figure 2 provides a graphical illustration of the operation principles just described. The main use cases are shown in Figure 3, which is fairly self-explanatory.
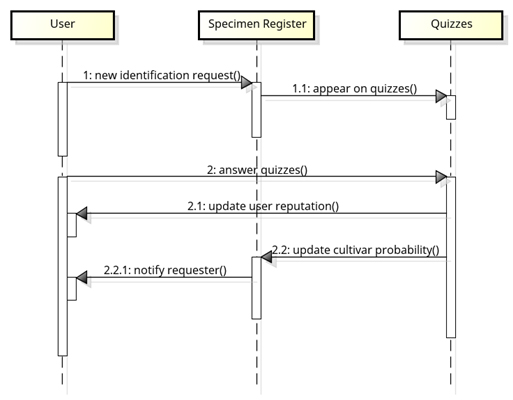 Figure 2. Simplified sequence diagram.
Figure 2. Simplified sequence diagram.
The system database may be empty to begin with, as it will be gradually fed by the identification requests; these can only be submitted by registered users. Quiz respondents must also be registered users, so that the system can keep track of their performance and update their rating accordingly.
To encourage participation, users may be rewarded based on number and completeness of identification forms submitted and/or performance as quiz respondents.
Since the philosophy of the system is to promote collaboration at global level, it will be designed to support multilingual user interface.
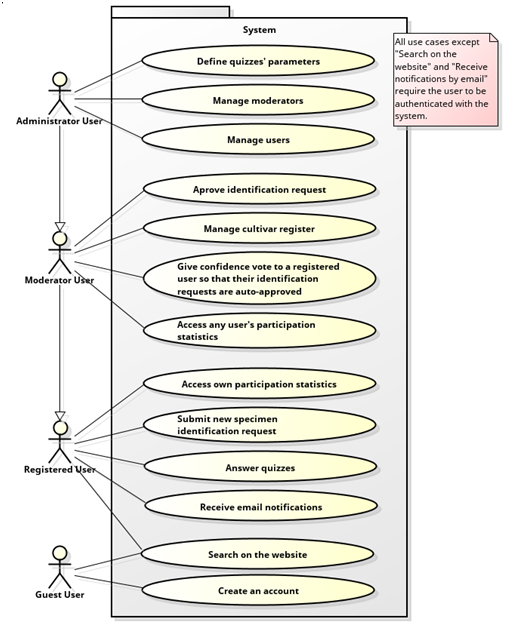 Figure 3. Basic system use case diagram.
Figure 3. Basic system use case diagram.
4. Specimen database
The specimen database, whose structure is illustrated in Figure 4 and Figure 5 by partial class diagram views, comprises fields for:
• Location of the garden (address and GPS coordinates);
• Location within the garden (identifying label or map-based pointer);
• Owner;
• Documented historic data (e.g. planting date, origin);
• Photographic documentation;
• Cultivar identification and associated probability (normally, dynamic fields worked out by the system);
• Characteristics according to UPOV guidelines (details below).
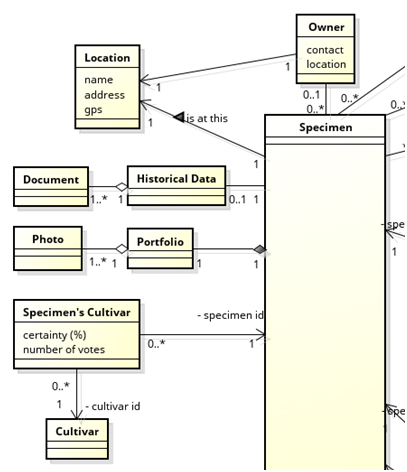 Figure 4. Partial view of the class diagram (main specimen data fields).
Figure 4. Partial view of the class diagram (main specimen data fields).
A set of 50 characteristics (49 morphological features and time of flowering) are considered, in accordance with the guidelines recently issued by the International Union for the Protection of New Varieties of Plants (UPOV) for conducting distinctness, uniformity and stability tests in the specific case of ornamental camellia varieties [11], based on work by Jiyuan Li et al. [12]. The morphological features (Figure 5) regard the plant as a whole (growth habit), its branches, foliage, vegetative buds, shoots, leaves, petioles, sepals, flower buds, flowers, petals, stamens, style, stigma and ovary.
Although the database is designed to allow storage of very complete and detailed specimen information, the identification request form will be kept simple and intuitive, with a minimum number of mandatory fields – possibly just the precise location of the specimen and a photo of a flower meeting certain minimum technical criteria in terms of colour, resolution and format, so it can be included in quizzes. The remaining fields will be optional, and users will be allowed to update in their identification requests at any point, so as not to discourage submission.
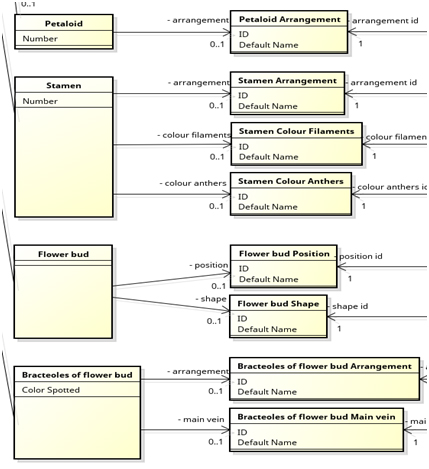 Figure 5. Partial view of the class diagram (morphological features).
Figure 5. Partial view of the class diagram (morphological features).
5. Standard specimens
If the cultivar represented by a specimen is known with absolute certainty, a moderator user (or group of moderator users) with permission to do so can give that specimen the status of standard specimen; its characteristics then become automatically associated to the corresponding entry in the cultivar register. The answer to quizzes using standard specimens is objective; so long as there are enough of them in the system, reputation metrics can rely solely on objective data. Since the contribution of each response to an identification request is weighed according to the reputation of the respondent, this makes the system more reliable. In other words, if an effort is made to insert, as early as possible, a large number of specimens whose cultivar is known with absolute certainty, the operation of the system can be improved, with identifications converging more rapidly to the right answer. Moreover, for identification requests with at least some characteristics filled-in, and so long as the characteristics of the standard specimens are fully specified, the system can automatically assist the identification process by narrowing down the range of possible answers and detecting perfect matches, should they occur (in which case the specimen in question would be an obvious candidate to standard specimen).
6. Reputation and cultivar probability metrics
The reputation of the respondents is a figure of merit based on their quiz performance. Basing it only on questions referring to standard specimens, it can be computed very simply as the percentage of right answers. It is fair to assume that a user with higher reputation is more likely to correctly identify any given specimen. Therefore, in working out cultivar probability, i.e. the probability of a specimen belonging to a certain cultivar, the respondent’s reputation is the weighing factor applied to his or her response.
These two figures are not static, in the sense that they are recalculated whenever new quizzes are considered. Alternative, more complex reputation metrics can be envisaged to avoid reliance on standard specimens.
7. Future work
The system is currently being implemented according to the design and requirements described before. Reputation metrics based on all quiz answers (not only those referring to standard specimens) are being analysed. The following step will be a small-scale functional test with dummy data, the main goal being to validate and compare the statistical metrics applied. Upon successful completion of this test, the system will be fed with real data. We intend to establish collaboration with top camellia gardens (e.g. Botanic gardens, Gardens of Excellence) preferably equipped with computer-aided specimen management, to try and import a core of reliable data, including as many standard specimens as possible (especially of Portuguese origin). Simultaneously, to ignite the process, we plan to organise fieldwork in small, private camellia gardens to fill-in identification requests as completely as possible with the help of volunteer Botany students, and publicise the system to attract quiz respondents.
8. References
[1] Robson, B. (2008) “On the naming of 19th Century camellias”. International Camellia Journal, No. 40, pp. 44-49.
[2] Scheme for the Recognition of International Camellia Gardens of Excellence (n.d.), Int. Camellia Society. Retrieved October 28, 2012, from http://www.internationalcamellia.org/
[3] International Camellia Register. (n.d.), Int. Camellia Society. Retrieved February 13, 2014, from http://www.internationalcamellia.org/international-camellia-register
[4] Web Camellia Register. (n.d.). Retrieved February 13, 2014, from http://camellia.unipv.it/camelliadb2/
[5] Couselo, J. L., Vela, P., Salinero, C. and Sainz, M. J. (2010) “Characterization and differentiation of old Camellia japonica cultivars using single sequence repeat (SSRs) as genetic markers”. International Camellia Journal, No. 42, pp. 117-122.
[6] Stoner, M. F. (2010) “Identification, history, cultivation, and conservation of heritage camellias in Hawaii”. International Camellia Journal, No. 42, pp. 46-49.
[7] Crowder, F. S. (2011) “A personal search for pre-1900 camellia cultivars and their preservation”. International Camellia Journal, No. 43, pp. 45-46.
[8] Howe, Jeff (June 2, 2006). "Crowdsourcing: A Definition". Retrieved January 2, 2013, from http://crowdsourcing.typepad.com/cs/2006/06/crowdsourcing_a.html
[9] Treezilla - the monster map of trees. (n.d.). Retrieved February 13, 2014, from http://treezilla.org/
[10] OpenTreeMap Cloud - Tree map for engaging communities and managing urban ecosystems. (n.d.). Retrieved February 13, 2014, from https://www.opentreemap.org/
[11] Guidelines for the conduct of tests for distinctness, uniformity and stability - Camellia L. - TG/275/1 (October 20, 2011). Retrieved February 13, 2014, from http://www.upov.int/edocs/tgdocs/en/tg275.pdf
[12] Li, J., Ni, S., Li, X, Zhang, X. and Gao, J. (2008) “Developing the International Test Guideline of Distinctness, Uniformity and Stability for Ornamental Camellia Varieties”. International Camellia Journal, No. 40, pp. 112-118.
Web design by Tribal Systems